¶ Leffa: Advanced Person Image Generation with Virtual Try-On and Pose Transfer
Leffa, short for Learning Flow Fields in Attention, is a groundbreaking framework that enhances controllable person image generation. By enabling precise manipulation of both appearance (e.g., virtual try-on) and pose (e.g., pose transfer), Leffa outperforms previous methods by reducing fine-grained texture distortion while maintaining exceptional image quality.
The model is built on a diffusion-based baseline and introduces a novel attention-guided approach to ensure better attention to key areas of reference images, which improves the generation of person images. Let’s dive into what makes Leffa such an exciting development in AI-driven image generation.
Leffa’s Achievements and Updates
How to Use Leffa for Controllable Person Image Generation
Why Leffa Is Leading the Way in Person Image Generation
Bonus: Shakker AI - A Powerful Alternative for AI Image Generation
¶ What is Leffa?
Leffa is a unified framework designed for controllable person image generation. Unlike traditional methods that sometimes distort fine-grained details when transferring appearance or pose, Leffa uses flow fields in attention to guide the attention layers more effectively, ensuring that the image generation process remains faithful to the reference image’s details.
Leffa's key innovation is its regularization loss on the attention map, which trains the system to better focus on the corresponding regions in the reference image during generation. This model improves two key aspects of person image generation:
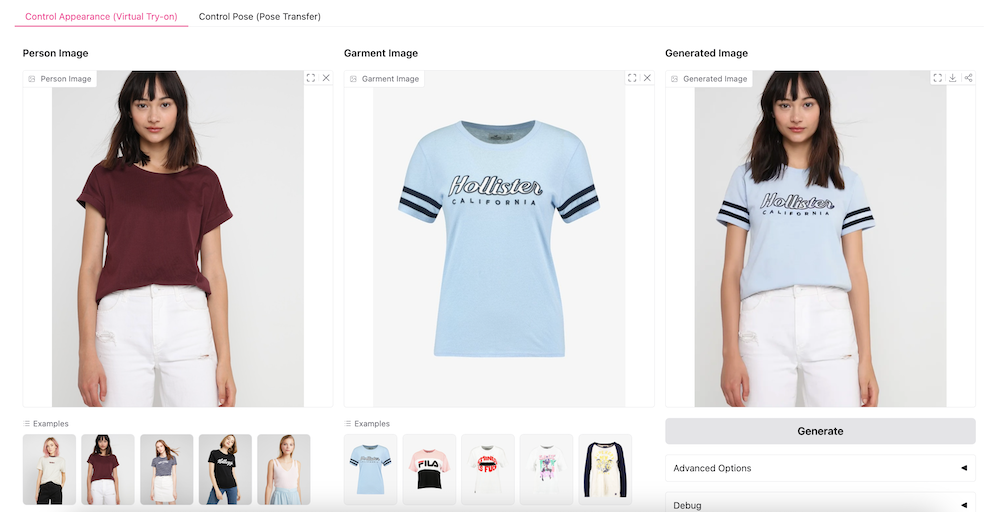
- Virtual Try-On: Changing a person’s clothes while preserving fine details of their appearance.
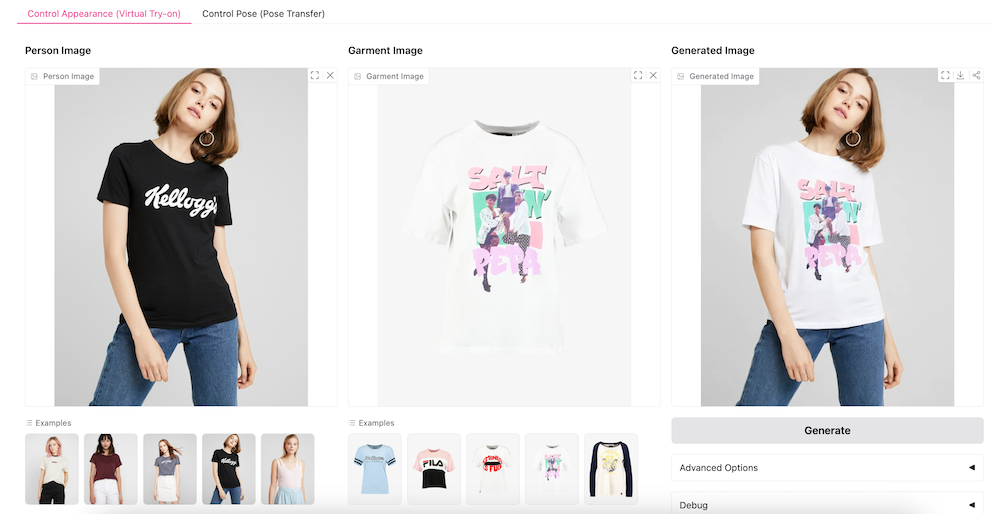
- Pose Transfer: Altering a person’s pose without losing the authenticity and texture of the original image.
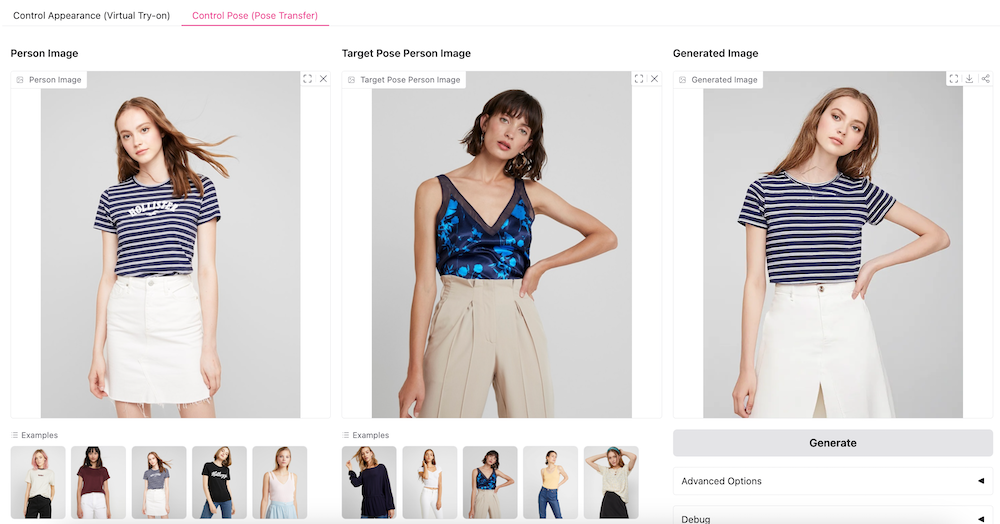
Leffa not only excels in quality but also reduces the distortion of fine details, making it ideal for applications that require high precision.
Key Features of Leffa:
-
Virtual Try-On: Generate realistic images with a virtual try-on feature that allows clothes to be placed on a person’s image seamlessly, maintaining the high fidelity of textures and details.
-
Pose Transfer: Modify the pose of a person in an image while retaining high-quality details, offering greater flexibility for creative and professional applications.
-
Attention to Detail: Leffa’s novel use of flow fields in attention reduces distortion in fine-grained areas like textures and clothing folds, making it a top choice for realistic image generation.
-
Model-Agnostic: Leffa’s loss function can be applied to other diffusion models, enhancing their performance in generating detailed and realistic images.
-
HuggingFace Integration: Leffa is available for use on HuggingFace, allowing developers to access the pre-trained model for their own projects and experiments.
For more information, check out the Leffa model on HuggingFace.
¶ Leffa’s Achievements and Updates
Recent updates to Leffa have significantly enhanced its performance:
-
January 2025: The model now defaults to float16, enabling faster inference with a 6-second image generation time on an A100 GPU.
-
December 2024: The mask generator was updated, improving the overall image generation results, and ref unet acceleration increased prediction speed by 30%. Additional controls were added in the Advanced Options to improve the user experience.
-
Virtual Try-On Model Release: Trained on DressCode and VITON-HD, this model is designed to enhance the virtual try-on experience with superior detail.
-
Pose Transfer Model: Trained on DeepFashion, it allows for natural and high-quality pose transfer with minimal distortion.
¶ How to Use Leffa for Controllable Person Image Generation
Leffa’s framework is accessible for both researchers and developers. To get started with Leffa:
Install Leffa by creating a conda environment and installing the necessary requirements:
| conda create -n leffa python==3.10
| conda activate leffa cd Leffa pip install -r requirements.txt |
|---|
-
Virtual Try-On: Use the pre-trained virtual try-on model for clothing generation, trained on DressCode and VITON-HD datasets. This allows you to place clothes on a person’s image while maintaining accurate textures and appearances.
-
Pose Transfer: Use the pose transfer model trained on DeepFashion to modify the pose of individuals in images while keeping the original details intact.
¶ Why Leffa Is Leading the Way in Person Image Generation
The ability to generate controllable images that respect the fine-grained details of a person's appearance and pose is a significant breakthrough. Leffa’s flow field attention not only addresses the traditional challenges of distortion but also empowers creators with more control over the image generation process. Its flexibility in virtual try-on and pose transfer tasks makes it a standout in the realm of AI image generation.
As Leffa continues to evolve, it holds promise for various industries, including fashion, entertainment, and digital content creation, where high-quality, realistic images are essential.
¶ Bonus: Shakker AI - A Powerful Alternative for AI Image Generation
While Leffa is a cutting-edge framework for controllable person image generation, if you’re looking for a flexible AI image generator in 2025, Shakker AI remains one of the best tools available. Shakker AI integrates Flux models, including models like Flex.1 alpha, and offers LoRA training, allowing for high-quality, customizable image generation.
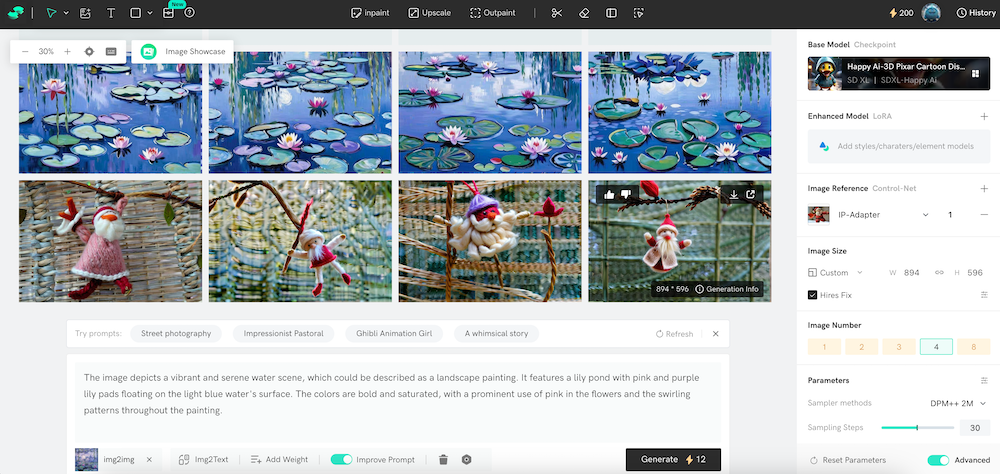
Shakker AI is perfect for those who require not just standard image generation but also fine-tuning and advanced editing capabilities. Whether you're working with text-to-image generation or exploring deep image edits like face-swapping or virtual try-on, Shakker AI can help you unlock endless creative possibilities.
¶ Final Thoughts
Leffa represents a monumental leap in controllable person image generation, focusing on reducing distortion and improving the accuracy of appearance and pose manipulation. With its recent updates and HuggingFace integration, Leffa continues to push the boundaries of AI image generation. Whether you’re creating virtual try-ons or pose transfers, Leffa offers a highly precise and efficient solution.
For those seeking a complete AI image generation suite, Shakker AI remains a powerful platform that integrates advanced Flux models, including Flex.1 alpha, for a robust creative workflow.
Explore Leffa and Shakker AI today to experience the future of AI-driven image creation!