¶ Introducing the OmniGen Model: A Powerful AI for Text-to-Image Generation
Today, we’re exploring OmniGen, a recently open-sourced model by the Beijing Academy of Artificial Intelligence (BAAI). OmniGen provides a seamless way to generate images with just a prompt—no need for Photoshop or ComfyUI! This guide walks you through deploying OmniGen, exploring its use cases, and showcases its image generation capabilities. Let’s dive in!
1. Introduction to the OmniGen Model
3. OmniGen Performance Overview
4. Deployment Guide: Setting Up OmniGen for Inference
5. Showcase: OmniGen Image Generation Examples
Shakker AI: The WebUI for OmniGen Model Implementation
¶ 1. Introduction to the OmniGen Model
OmniGen, developed by BAAI, is a groundbreaking diffusion-based architecture for image generation. Its unified design supports various use cases, including text-to-image generation, image editing, theme-driven creation, and vision-conditioned image generation.
¶ Key Features of OmniGen:
-
Unified Design: OmniGen excels in text-to-image generation while inherently supporting downstream tasks like image editing and visual condition-based generation.
-
Simplified Workflow: Its streamlined architecture eliminates the need for extra plugins. Tasks are executed end-to-end with instructions, simplifying complex workflows.
-
Knowledge Transfer: OmniGen effectively transfers knowledge between different tasks, enabling novel capabilities in unseen tasks and domains.
-
Open Source: Licensed under MIT, OmniGen has already seen over 58.5k downloads on Hugging Face.
¶ 2. OmniGen Model Architecture
OmniGen integrates VAE (Variational Autoencoders) and pretrained Transformer models. It supports multimodal inputs and enhances image generation with optimized attention mechanisms. During training, the model incrementally increases image resolution for better outcomes. Below is a simplified architecture diagram:
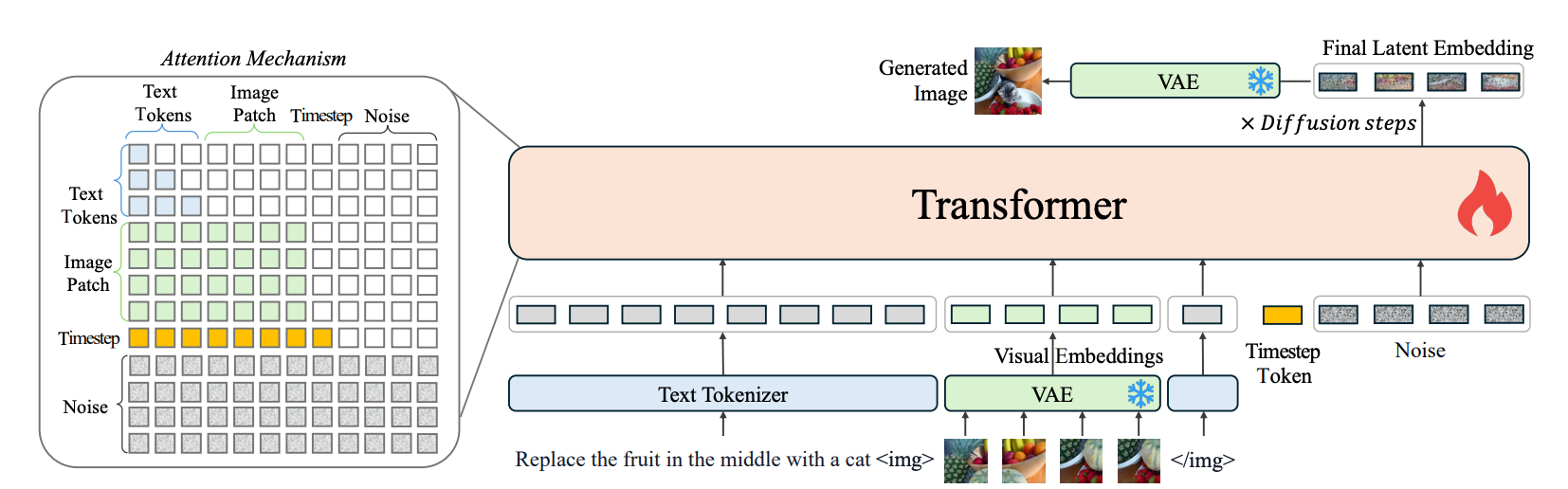
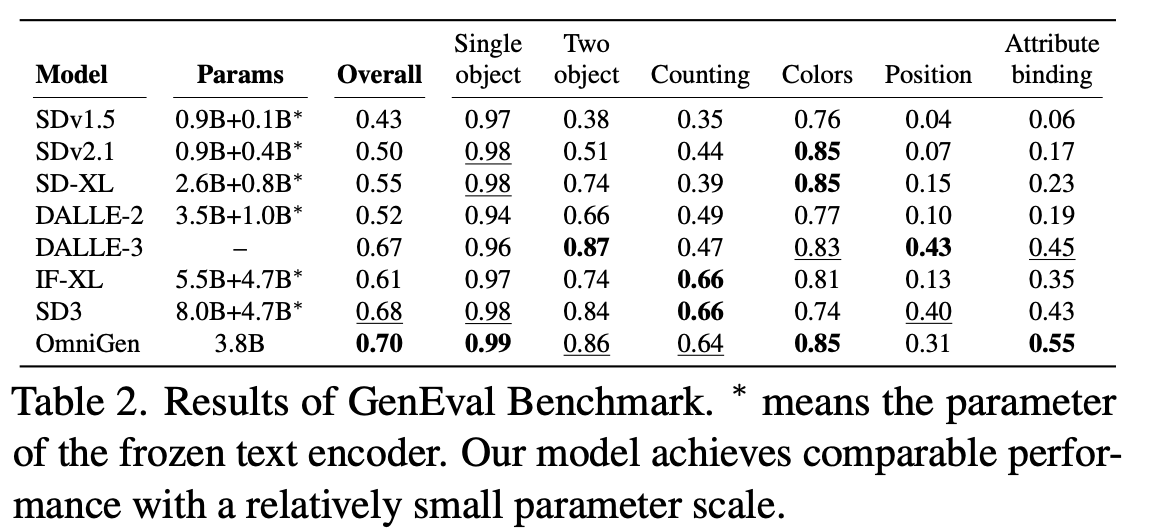
¶ 3. OmniGen Performance Overview
OmniGen performs comparably to leading diffusion models, despite having fewer parameters. The benchmarks on GenEval demonstrate its efficiency and effectiveness.
¶ 4. Deployment Guide: Setting Up OmniGen for Inference
¶ Step 1: Configure the Python Environment
Run the following commands to set up OmniGen:
| !git clone https://github.com/VectorSpaceLab/OmniGen.git %cd OmniGen !pip install -e . !pip install gradio spaces clear_output() !ls |
|---|
¶ Step 2: Download OmniGen Model Weights
| from OmniGen import OmniGenPipeline pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1") |
|---|
Note: The model requires approximately 8GB of GPU memory.
¶ Method 1: Script-Based Inference
For text-to-image generation:
| images = pipe( prompt="A curly-haired man in a red shirt is drinking tea.", height=512, width=512, guidance_scale=2, img_guidance_scale=1.6, seed=0, ) images[0].save("example_t2i.png") |
|---|
For multimodal image generation:
| images = pipe( prompt="A man and a woman are hugging each other. A man is <img><|image_1|></img>. A woman is <img><|image_2|></img>.", input_images=["/path/to/man.jpg", "/path/to/woman.jpg"], height=512, width=512, separate_cfg_infer=True, guidance_scale=3, img_guidance_scale=1.6 ) images[0].save("example_ti2i.png") |
| :---- |
¶ Method 2: Gradio UI for Interface-Based Generation
To launch the Gradio UI:
| !npm install -g localtunnel !python app.py |
|---|
Once running, the interface will allow you to input prompts (in English) and reference images to generate results interactively.

¶ 5. Showcase: OmniGen Image Generation Examples
¶ Example 1: Text-to-Image Generation
With increasingly detailed prompts, OmniGen delivers stunning results:
| Prompt | Output Image |
|---|---|
| A curly-haired man in a red shirt is drinking tea. |  |
| A tiger is roaring towards the sky on a mountaintop. 4K, HD | 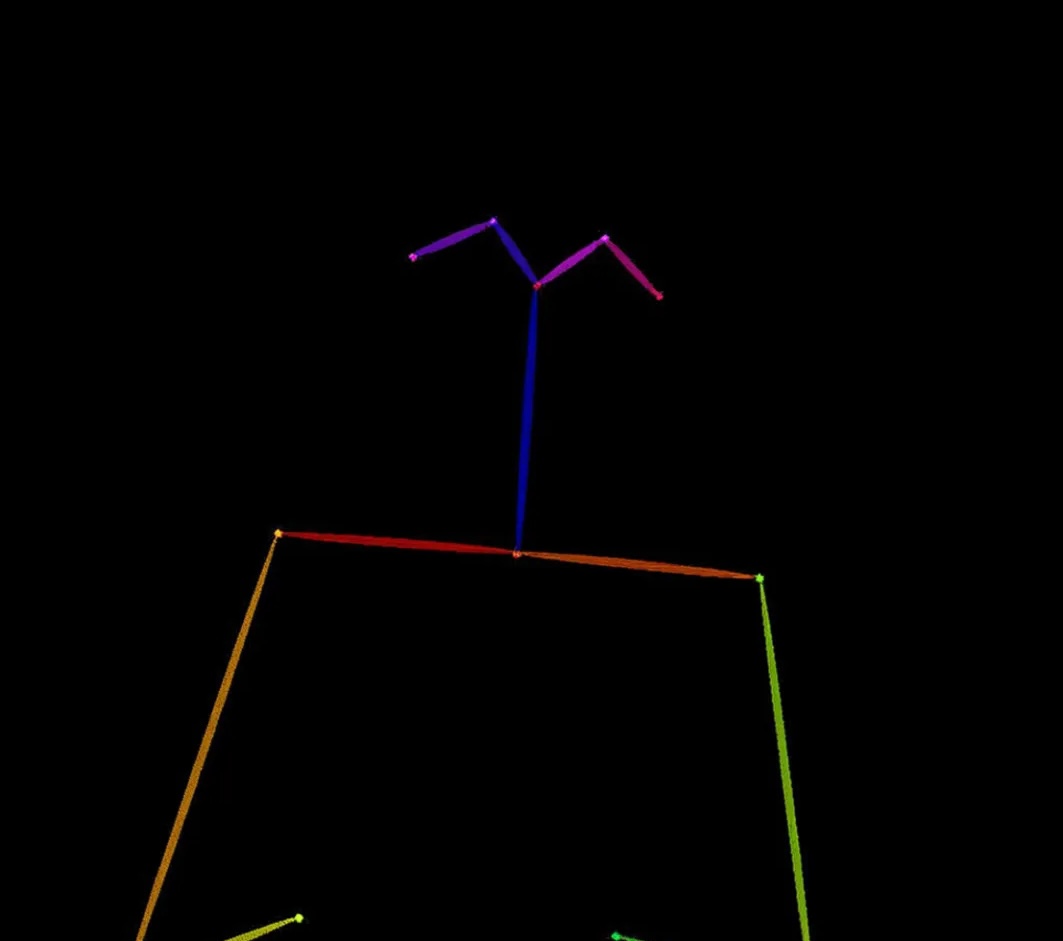 |
| Realistic photo. A young woman sits on a sofa, holding a book and facing the camera. She wears delicate silver hoop earrings adorned with tiny, sparkling diamonds that catch the light, with her long chestnut hair cascading over her shoulders. Her eyes are focused and gentle, framed by long, dark lashes. She is dressed in a cozy cream sweater, which complements her warm, inviting smile. Behind her, there is a table with a cup of water in a sleek, minimalist blue mug. The background is a serene indoor setting with soft natural light filtering through a window, adorned with tasteful art and flowers, creating a cozy and peaceful ambiance. 4K, HD. | |
¶ Example 2: Single-Reference Multimodal Image Generation
| Prompt | Input Image | Output Image |
|---|---|---|
| Remove the woman's earrings. Replace the mug with a clear glass filled with sparkling iced cola. | ![] |
|
| Detect the skeleton of human in this image. | |
|
¶ Example 3: Multi-Reference Multimodal Image Generation
| Prompt | Image 1 | Image 2 | Output Image |
|---|---|---|---|
| A professor and a boy are reading a book together. The professor is the middle man in imag1 The boy is the boy holding a book in image_2." |  |
 |
 |
¶ ---
OmniGen is an innovative and user-friendly tool for image generation tasks. Try it today and unlock new possibilities in AI-powered creativity!
¶ ---
¶ Shakker AI: The WebUI for OmniGen Model Implementation
In recent advancements of AI-driven image generation, the OmniGen model, developed by Beijing Academy of Artificial Intelligence (BAAI), has emerged as a versatile and unified diffusion model. Complementing this powerful model is Shakker AI, an intuitive WebUI platform that simplifies deployment, experimentation, and results visualization. By integrating Shakker AI as the user interface for the OmniGen model, users can unlock an accessible and streamlined workflow for generating stunning visuals.
¶ Why Use Shakker AI with the OmniGen Model?
- User-Friendly Interface:
Shakker AI provides a seamless GUI (Graphical User Interface) to operate OmniGen's capabilities, eliminating the need for command-line complexities.
- Simplified Workflow:
From loading model weights to inputting prompts or reference images, Shakker AI allows users to manage the OmniGen pipeline with just a few clicks.
- Integrated Multi-Modal Support:
Shakker AI supports OmniGen’s multi-modal inputs, making it easy to create images based on text prompts or a combination of text and reference images.
- Real-Time Adjustments:
With Shakker AI, users can tweak parameters such as resolution, guidance scale, and seed in real time, observing results interactively.
- Collaboration and Accessibility:
The WebUI supports deployment on local servers or the cloud, making it accessible for teams or individual users.