¶ LoRA X: Revolutionizing AI Model Serving with Shakker AI
Artificial Intelligence (AI) is constantly evolving, and with it comes a demand for better, faster, and more scalable solutions to serve fine-tuned models. Enter LoRA X, a groundbreaking platform that redefines AI model serving. Capable of hosting thousands of fine-tuned models on a single GPU, LoRA X slashes latency and costs, making AI more accessible to businesses and developers alike.
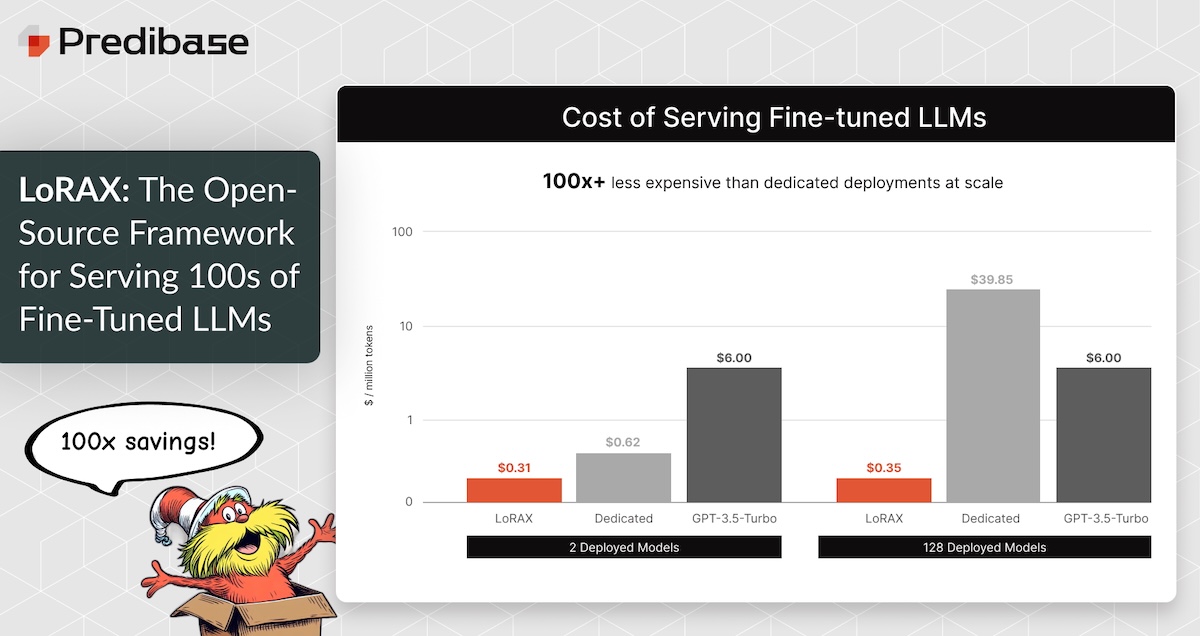
At the forefront of this movement are frameworks like Predibase LoRAX and innovative tools like Shakker AI, which together simplify and scale AI workflows. Let’s explore how LoRA X is revolutionizing AI model serving and why it’s a game-changer for the industry.
How to Get Started with LoRA X
¶ What is LoRA X?
LoRA X is a cutting-edge LoRA exchange platform built to address the challenges of serving and deploying large language models (LLMs) and fine-tuned adapters. Traditionally, hosting fine-tuned models required substantial computational resources, often leading to high costs and limited scalability. LoRA X disrupts this paradigm by enabling dynamic adapter loading and efficient GPU utilization, allowing the deployment of smaller, cost-effective fine-tuned open-source LLMs with minimal latency.
The platform is designed with flexibility and efficiency in mind. By dynamically loading fine-tuned models on demand, LoRA X removes the bottlenecks that often plague traditional AI model servers. This scalability ensures seamless handling of thousands of fine-tuned models, making it a preferred choice for enterprises and developers aiming to optimize their AI pipelines.
Predibase LoRAX, one of LoRA X’s core contributors, enhances the platform further by introducing multi-turn chat support, real-time model integration, and intelligent GPU resource allocation. These features enable users to deploy sophisticated conversational agents and advanced AI models without breaking the bank.
¶ Key Features of LoRA X
LoRA X’s advanced capabilities make it a standout solution for AI model serving. Below are the features that set it apart:
¶ 1. Dynamic Adapter Loading
LoRA X enables real-time loading of fine-tuned LoRA adapters without interrupting ongoing requests. This feature ensures that users can switch between models seamlessly, catering to diverse use cases.
¶ 2. Heterogeneous Continuous Batching
This feature optimizes throughput by handling multiple concurrent requests efficiently. By leveraging intelligent batching techniques, LoRA X reduces waiting times, even under heavy workloads.
¶ 3. High Throughput & Low Latency
Thanks to advanced optimizations such as Flash Attention and pre-compiled CUDA kernels, LoRA X delivers unmatched performance. These optimizations ensure low-latency responses, even when handling complex queries or large-scale operations.
¶ 4. Production-Ready Infrastructure
LoRA X is designed for production environments, offering tools like:
- Pre-built Docker images for easy setup.
- Kubernetes Helm charts for scalable deployments.
- OpenAI-compatible API for seamless integration.
- JSON output support for versatile data handling.
¶ 5. Compatibility with Predibase and Shakker AI
LoRA X integrates smoothly with fine-tuned models from Predibase LoRAX and Shakker AI, enabling the creation of dynamic ensembles on demand. This compatibility allows users to leverage the strengths of multiple models, enhancing the overall output quality.
With these features, LoRA X provides a robust, scalable solution for enterprises looking to harness the power of AI without incurring prohibitive costs.
¶ Shakker AI: Elevating LoRA X
While LoRA X excels at serving fine-tuned models, Shakker AI takes model creation and deployment to the next level. Designed as an all-in-one platform, Shakker AI integrates seamlessly with LoRA technology, making it a perfect companion for LoRA X users.
¶ Key Features of Shakker AI
- Custom Model Generation
Shakker AI supports prompt-based workflows, img2img, and model-specific settings, enabling users to create tailored AI models with precision.
- Canvas Tools
The platform offers advanced editing tools, such as inpainting, outpainting, background removal, and smart cropping. These features empower users to fine-tune their models for specific tasks, from image generation to content creation.
- Integration with Popular Frameworks
Shakker AI is compatible with A1111 WebUI, ComfyUI, and LoRA training workflows, providing a unified interface for managing diverse projects.
- Support for Diverse Model Types
Whether it’s SD for photorealistic images, Flux for artistic designs, or NoobAI for anime-style outputs, Shakker AI enables seamless deployment and integration within the LoRA X ecosystem.
By bridging the gap between model creation and deployment, Shakker AI enhances the capabilities of LoRA X, ensuring users have access to a comprehensive toolkit for AI development.
¶ How to Get Started with LoRA X
Setting up LoRA X is straightforward, thanks to its production-ready infrastructure. Below is a step-by-step guide to help you get started:
¶ Requirements
- Linux OS: A stable operating system environment.
- NVIDIA GPU: Minimum Ampere architecture for optimal performance.
- Docker: Essential for containerized deployment.
¶ Setup
- Launch the LoRAX Server
Use the pre-built Docker image to initialize the LoRA X server. The process is streamlined, ensuring minimal configuration.
- Integrate Fine-Tuned Models
Add your fine-tuned models and adapters. LoRA X supports dynamic adapter loading, making integration a breeze.
- Deploy on Kubernetes
For high availability and scalability, deploy LoRA X on Kubernetes using the provided Helm charts.
¶ Use Cases
- API Integration
Prompt models using LoRA X’s REST API or Python client for seamless integration into your workflows.
- Custom Model Creation
Leverage Shakker AI to create tailored models, optimize workflows, and enhance your AI capabilities.
With these steps, users can unlock the full potential of LoRA X, leveraging its scalability and efficiency for diverse AI applications.
¶ Final Words
LoRA X is more than just a platform; it’s a revolution in AI model serving. By enabling the seamless deployment of thousands of fine-tuned models on a single GPU, LoRA X democratizes AI, making it accessible and affordable for businesses and developers. Its integration with tools like Predibase LoRAX and Shakker AI further enhances its value, offering users a comprehensive ecosystem for AI model creation and deployment.
Whether you’re looking to optimize your AI workflows, reduce costs, or scale your operations, LoRA X and Shakker AI provide the tools and infrastructure to achieve your goals. Explore these technologies today and take the next step in your AI journey!
¶ Related Posts
- Everything About LoRA Model: Shakker AI’s Ultimate Guide >>
- Choosing the Right Base Model for Effective LoRA Training >>
- Understanding Key Parameters in LoRA Training: Epoch, Batch Size, and Precision >>
- Comprehensive Guide to Optimizers and Training in LoRA >>