¶ Comprehensive Tutorial to LoRA Training & Tools
When discussing model training, LoRA (Low-Rank Adaptation) has become an indispensable topic in the AI image generation field. However, the complexity of training a LoRA model often makes it challenging for newcomers. In this guide, we’ll take you through a clear step-by-step process for training a successful LoRA model.
- 1. Determine the Type of LoRA Model
- 2. Collect an Appropriate Training Dataset
- 3. Process the Training Dataset
- 4. Select a Suitable Base Model
- 5. Adjust Training Parameters
- 6. Validate the LoRA Model
Step 1: Choosing the Right LoRA Training Model
Step 2: Collecting the Right Training Dataset
Step 3: Training Dataset Processing
- 1. Adjusting Training Images to the Optimal Resolution
- 2. Selecting Labeling Methods Based on Model Type
Step 4. Choosing the Right Base Model
Step 5. Adjusting Training Parameters
- a. Learning Rate
- b. Batch Size
- c. Training Epochs
- d. Regularization Parameter
- e. Optimizer-Specific Parameters
2. Adjusting Training Parameters for Different Datasets
- 1. Differences in Image Content
- 2. Diversity of Image Styles
- 3. Risk of Overfitting
- 4. Risk of Underfitting
The Easiest Way to Train a LoRA Model
¶
¶ What is LoRA?
¶ 1. Definition of LoRA
Before diving into the training process, it’s crucial to understand what LoRA is.
LoRA is a technique used for model fine-tuning, widely applied across various deep learning fields. In image generation, LoRA allows users to fine-tune a base model for specific styles (e.g., anime, realism) or themes (e.g., characters, scenes). This results in high-quality, style-specific images while leveraging the base model's pre-trained knowledge and capabilities.
¶ 2. Advantages of LoRA
Why should you opt for LoRA training instead of directly fine-tuning a large model? Here are the key benefits:
01. Compact File Size
LoRA models are significantly smaller compared to other fine-tuning methods, with sizes ranging from 2MB to 200MB. This makes them highly portable, ideal for storage, and easy to share. Users can manage a large collection of LoRA models tailored to different styles and use cases.
02. High Training Efficiency
LoRA requires training only a small number of parameters, leading to faster training speeds and reduced computational resource consumption. This is perfect for users seeking quick results for specific styles or characters.
03. Strong Customizability
LoRA offers unparalleled flexibility, allowing users to train models tailored to specific characters, art styles, or concepts. For instance:
-
Train a LoRA model for a specific anime character to perfectly replicate its appearance and traits.
-
Create a model based on a particular art style, such as impressionism, enabling Stable Diffusion to generate images adhering to that style.
This level of customization ensures results closely align with user expectations.
¶ Steps to Train a LoRA Model
Although the process can seem complex, training a LoRA model can be broken down into six key stages:
¶ 1. Determine the Type of LoRA Model
The first step is identifying your specific needs to determine the type of LoRA you wish to train. For instance:
- If your goal is to generate artistic images in a classical oil painting style, you must focus on characteristics like color usage, brushstroke tendencies, and compositional nuances.
¶ 2. Collect an Appropriate Training Dataset
High-quality data is essential for success. Gather a diverse collection of images that fit the desired style or theme. These images should vary in composition, color palettes, and subjects but remain cohesive within the specified style.
¶ 3. Process the Training Dataset
Prepare the images by standardizing their dimensions and resolution. This ensures consistency during training, which is critical for achieving optimal results.
¶ 4. Select a Suitable Base Model
Choose a base model that aligns with your objectives. For example:
-
Some base models excel in generating realistic, detailed images.
-
Others are better suited for artistic or surreal imagery.
¶ 5. Adjust Training Parameters
Fine-tune parameters such as learning rate, batch size, and training iterations. Continuously optimize these settings to strike the perfect balance between quality and efficiency.
¶ 6. Validate the LoRA Model
Test the trained model thoroughly to ensure it meets your expectations. Use various prompts to evaluate whether the generated images accurately reflect the desired style and quality.
¶ Step 1: Choosing the Right LoRA Training Model
The Shakker AI Online Training Tool offers multiple training model options tailored to your needs. These include:
-
Base Model 1.5 (Portraits, ACG, Art Styles)
-
Base Model XL (SDXL)
-
Base Model F.1 (FLUX)

¶ 01. Base Model 1.5
Overview:
This is a relatively foundational and stable model, suitable for general image generation tasks. While it provides reliable results for common themes and styles, its performance in terms of detail richness and complexity may not match that of SDXL or FLUX.
Key Features:
-
Generates moderate-quality images that effectively capture basic shapes, colors, and themes (e.g., simple landscapes, portraits).
-
Performs adequately for standard use cases but may lack sophistication in light, shadow effects, and intricate textures.
-
Comes with three preset configurations for ease of use.
Advantages:
-
Requires lower computational resources, making it cost-effective for training.
-
Ideal for users with limited hardware or less demanding image generation goals.
¶ 02. Base Model XL (SDXL)
Overview:
This model delivers superior performance and can generate high-quality, high-resolution images. It excels in fine detail reproduction, color depth, and handling complex scenes.
Key Features:
-
Ideal for creating large-scale, intricate environments (e.g., cityscapes, detailed sci-fi settings).
-
Produces highly accurate character renderings, capturing subtle facial expressions, hair textures, and other fine details.
Advantages:
-
Significantly enhances realism and detail quality in output.
-
Perfect for high-end projects requiring exceptional precision and aesthetics.
Considerations:
- Demands higher computational resources compared to Base Model 1.5, resulting in increased training costs.
¶ 03. Base Model F.1 (FLUX)
Overview:
Building on the capabilities of SDXL, the F.1 model further enhances detail precision and scene complexity. It emphasizes innovation and flexibility, making it well-suited for unique styles or emerging creative demands.
Key Features:
-
Excels in generating highly realistic and distinctive images, such as lifelike portraits and scenes with special visual effects (e.g., surreal lighting, unique color palettes).
-
Particularly effective for handling tasks requiring artistic experimentation or non-traditional outputs.
Advantages:
-
Optimized for specialized, high-fidelity image generation needs.
-
Delivers standout results in creative applications where standard models may fall short.
Considerations:
- Requires the highest computational resources among the three models, leading to greater training costs.
¶ Step 2: Collecting the Right Training Dataset
¶ 1. Importance of the Training Dataset for LoRA
The saying “A good dataset equals a good LoRA” is widely recognized in the model training community. Why is this the case? Here are the key reasons:
Foundation for Feature Learning:
A training dataset provides the source material for LoRA to learn features. A well-curated dataset includes diverse texts and images, enabling LoRA to grasp the connections between the two. For example, if the dataset contains a large number of textual descriptions about “landscapes” and corresponding images, LoRA can learn visual features associated with “landscapes”—like mountain shapes, sky colors, tree textures—and their relationships to the corresponding text.
Guidance for Fine-Tuning Direction:
The design of the dataset determines the fine-tuning focus of LoRA. If the dataset emphasizes a particular style, such as oil painting, LoRA will adjust to produce images in that style. Carefully curated text-image pairs, such as “an oil-painting style sunrise by the sea” alongside relevant images, help LoRA learn how to modify outputs to match specific features of the style, like brush textures and saturated colors.
Enhanced Generalization Ability:
A well-designed dataset improves LoRA's ability to generalize. By including a wide variety of scenarios, objects, and styles, LoRA avoids being restricted to a narrow range of outcomes. For instance, a dataset that includes not only landscapes but also portraits, architecture, and animals across various styles (realistic, cartoon, abstract) enables LoRA to meet diverse user requirements during image generation.
Reduced Overfitting Risk:
A suitable training dataset helps prevent overfitting, where the model performs well only on training data but poorly on new data. By ensuring sufficient diversity and properly splitting the dataset into training, validation, and testing subsets, LoRA can learn general patterns rather than memorizing specific examples. For instance, a sufficiently large and balanced dataset prevents LoRA from overfitting to unique features of a small subset, resulting in better performance across diverse inputs.
¶ 2. The Equivalence of a Good Dataset and a Good LoRA
From a results perspective, a good dataset allows LoRA to generate high-quality, style-consistent images after fine-tuning. If the dataset effectively conveys the characteristics of a specific art style, LoRA can integrate that style into its outputs just as well as a specialized, high-quality LoRA designed for that style.
When adapting to new tasks, a good dataset enables LoRA to quickly generate images for specific themes or moods, such as “cozy and warm” or “medieval European culture.” This parallels the capabilities of a purpose-built LoRA for those tasks, fulfilling diverse image-generation needs.
¶ 3. Examples of LoRA Training Dataset Design
The design of training datasets for LoRA varies by type, typically falling into two main categories: portraits and art styles. Each has unique considerations, as detailed below:
¶ 01. Portraits
For single-subject portrait datasets, a collection of approximately 100 images strikes the right balance for effective training. Too many images increase complexity, while too few risk overfitting.
Key design guidelines for a 100-image dataset:
-
Angles: Include images from the front, side, and back views.
-
Distances: Cover close-ups, medium shots, and full-body shots.
-
Details: Vary expressions, poses, and outfits for each angle and distance.
| Category | Front View | Side View | Back View | Total |
|---|---|---|---|---|
| Close-ups | ~25 images | ~15 images | ~5 images | ~45 images |
| Medium shots | ~20 images | ~15 images | ~5 images | ~40 images |
| Full-body | ~5 images | ~5 images | ~5 images | ~15 images |
| Total | ~50 images | ~35 images | ~15 images | ~100 images |
Tips for collecting portrait datasets:
-
Close-ups: Include diverse facial expressions (happy, serious, surprised), poses (standing, sitting, walking), and outfits (formal, casual, cultural attire).
-
Medium shots: Capture subjects in various settings (indoor, outdoor, street, park) and actions (running, jumping, conversing, working).
-
Full-body: Highlight the subject within larger scenes (cityscapes, nature) to showcase their overall form.
-
Image quality: Ensure all images are clear, relevant, and diverse.
A carefully designed portrait dataset improves LoRA’s ability to reproduce realistic and versatile portraits across multiple scenarios.
¶ 02. Art Styles

For art style training, 200 images are often ideal. This number provides enough information for LoRA to learn diverse representations of scenes, characters, and objects without overly complicating the training process. Adjustments can be made based on available resources and project goals.
Designing a 200-image art style dataset:
-
Scene Variety: Include indoor and outdoor scenes.
-
Angles: Incorporate special angles, such as low-angle and top-down shots.
Indoor Scene Examples:
-
Close-ups (15 images): Focus on details like toy textures, table colors, and patterns to highlight the style’s intricacy.
-
Medium shots (20 images): Showcase interactions between characters and objects, teaching spatial coordination.
-
Wide shots (10 images): Capture entire room layouts, such as bedroom furniture arrangements, for spatial understanding.
Outdoor Scene Examples:
-
Close-ups (5 images): Highlight natural elements like flowers and grass textures.
-
Medium shots (20 images): Include playgrounds and skies to show environment interactions.
-
Wide shots (10 images): Feature landscapes to enhance LoRA’s sense of composition and scale.
Special Angles (10 images): Include low-angle (to emphasize height) and top-down shots (for layout comprehension).
| Scene Type | Perspective | Description | Image Count |
|---|---|---|---|
| Indoor Scenes | Close-ups | Teach LoRA to capture detailed textures and features, like furniture patterns or lighting. | 15 images |
| Medium shots | Show character-object interactions and interior layouts, building spatial awareness. | 20 images | |
| Wide shots | Help LoRA understand full indoor compositions and atmospheres, such as cozy living spaces. | 10 images | |
| Outdoor Scenes | Close-ups | Highlight natural details like plants, skies, or playground elements, enhancing texture understanding. | 5 images |
| Medium shots | Showcase dynamic character movements within outdoor environments, fostering scene adaptability. | 20 images | |
| Wide shots | Teach LoRA to replicate large-scale scenes like forests or cityscapes, focusing on composition and color blending. | 10 images | |
| Special Angles | Low/High Angles | Provide unique perspectives to enrich LoRA’s spatial comprehension and stylistic diversity (e.g., looking up at tall buildings or down on courtyards). | 10 images |
Characters and Objects:
- Characters
Characters are one of the core elements in cartoon art styles. This category includes a diverse range of cartoon figures representing different ages, genders, and ethnicities—such as children, teenagers, and adults, along with boys, girls, and individuals with various skin tones. These characters are also depicted with a wide range of facial expressions (e.g., happiness, surprise) and actions (e.g., running, jumping), paired with a variety of outfits, including school uniforms, sportswear, traditional costumes, and fantasy attire.
Such diversity allows the model to comprehensively learn about different features and expressions of characters, enabling it to generate a wide array of cartoon figures that cater to various creative needs. Because of this, characters make up a significant portion of the training dataset.
- Animal Characters
Animal characters are another common element in cartoon-style imagery, offering unique shapes and personality traits. This category includes familiar animals like cats, dogs, and rabbits, as well as fantastical creatures such as unicorns and dragons. These additions enhance the diversity of the training dataset.
By learning the visual characteristics of different animals and their interactions in various settings, the model gains the ability to stylize animals in cartoon art and integrate them seamlessly with other elements. This enriches the overall variety and playfulness of the generated images.
- Objects and Props
Everyday objects and props—such as food, vehicles, school supplies, and toys—are essential for building vibrant cartoon scenes. The design of these elements involves simplified shapes, exaggerated colors, and seamless integration into the cartoon style.
Through exposure to a wide range of objects and props, the model can learn how to accurately represent these items in a cartoon setting, resulting in more diverse and realistic outputs. For example, learning the bold colors and whimsical shapes of cartoon cakes or the playful designs of vehicles allows the model to master the art of rendering objects in a cartoon style.
Types of Characters and Objects
| Type | Description | Number of Images (Example) |
|---|---|---|
| Characters | Covers different ages, genders, ethnicities, facial expressions, and actions, paired with a variety of outfits. Core element of the dataset, occupying a significant proportion. | 60 images |
| Animal Characters | Includes common animals and fantastical creatures, enriching the dataset's diversity and teaching stylization and interaction in cartoon settings. | 30 images |
| Objects and Props | Includes items like food, vehicles, school supplies, and toys, helping the model learn to stylize objects and enrich cartoon scenes. | 20 images |
¶ Step 3: Training Dataset Processing
The preparation of the training dataset is a critical step that directly impacts the quality of the final model. Proper handling of the dataset ensures optimal results. Training dataset processing typically involves two key tasks: adjusting images to the final resolution and labeling the training dataset. Below are the details:
¶ 1. Adjusting Training Images to the Optimal Resolution
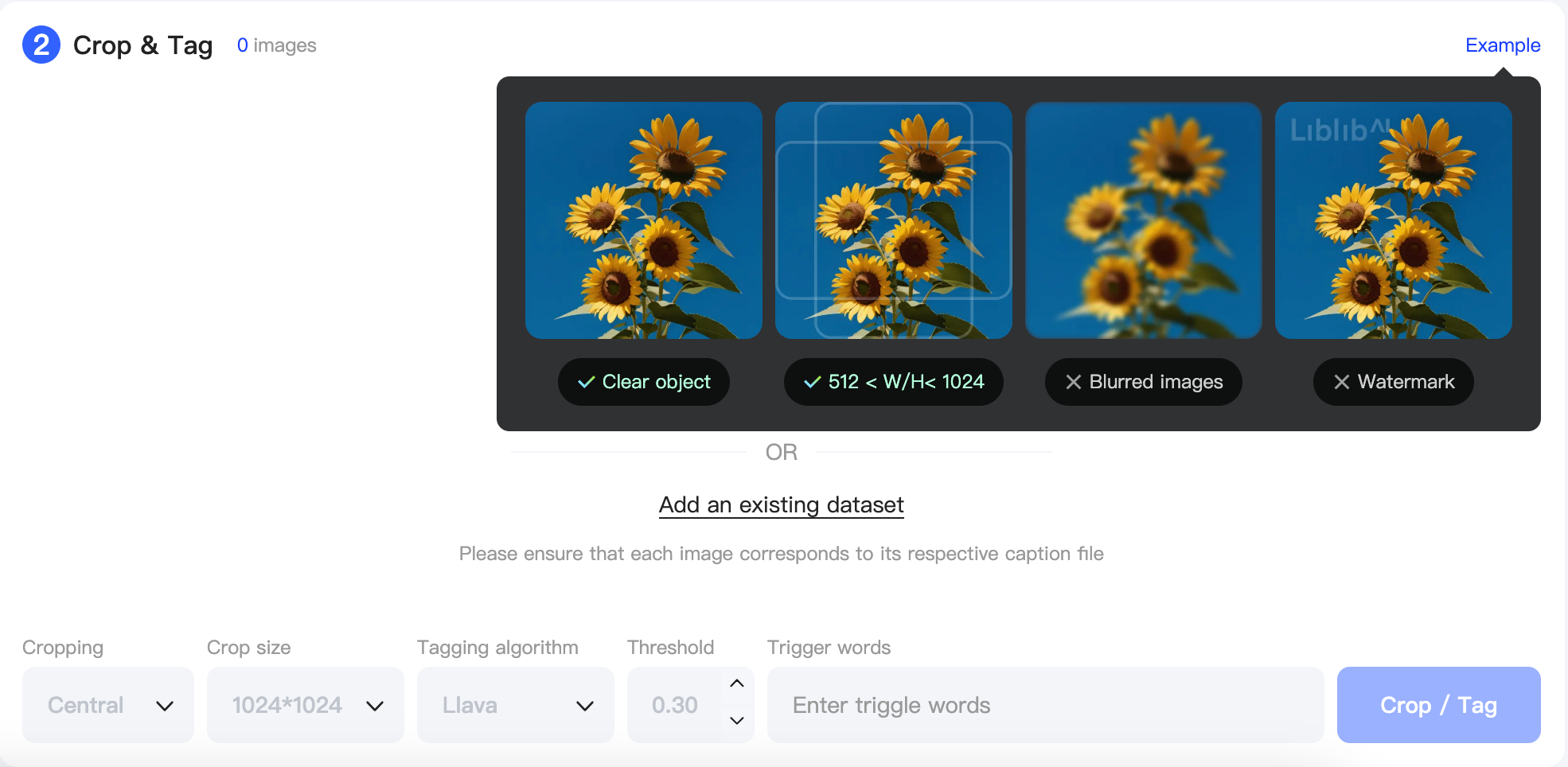
The Shakker AI Online Training Tool offers two cropping methods to help you efficiently crop images with a single click. Cropping images provides the following benefits:
Reducing Computational Load
Original images often have large dimensions and intricate details. However, not all pixel information is essential for model training. Cropping reduces the image size to a manageable range—commonly to dimensions like 512×512, 512×768, or 768×512.
This reduction significantly decreases the amount of data the model processes during training, leading to faster training times. The efficiency boost is particularly evident when working with large-scale datasets, allowing for more training iterations or quicker completion of training tasks under limited computational resources.
Focusing on Key Information
Cropping helps eliminate irrelevant or redundant information from images, allowing the model to focus on learning the core features critical to the task. For instance, when training a model to recognize specific objects, original images may contain excessive background details. Cropping narrows the focus to the object itself, enhancing the model's learning process.
By concentrating on task-relevant regions, the model can achieve better performance more quickly, as it avoids wasting computational resources on pixels unrelated to the task objective. This ultimately improves both the efficiency and effectiveness of training.
¶ 2. Selecting Labeling Methods Based on Model Type
The Shakker AI Online Training Tool offers five labeling methods to assist with one-click image annotation. Here's an overview:
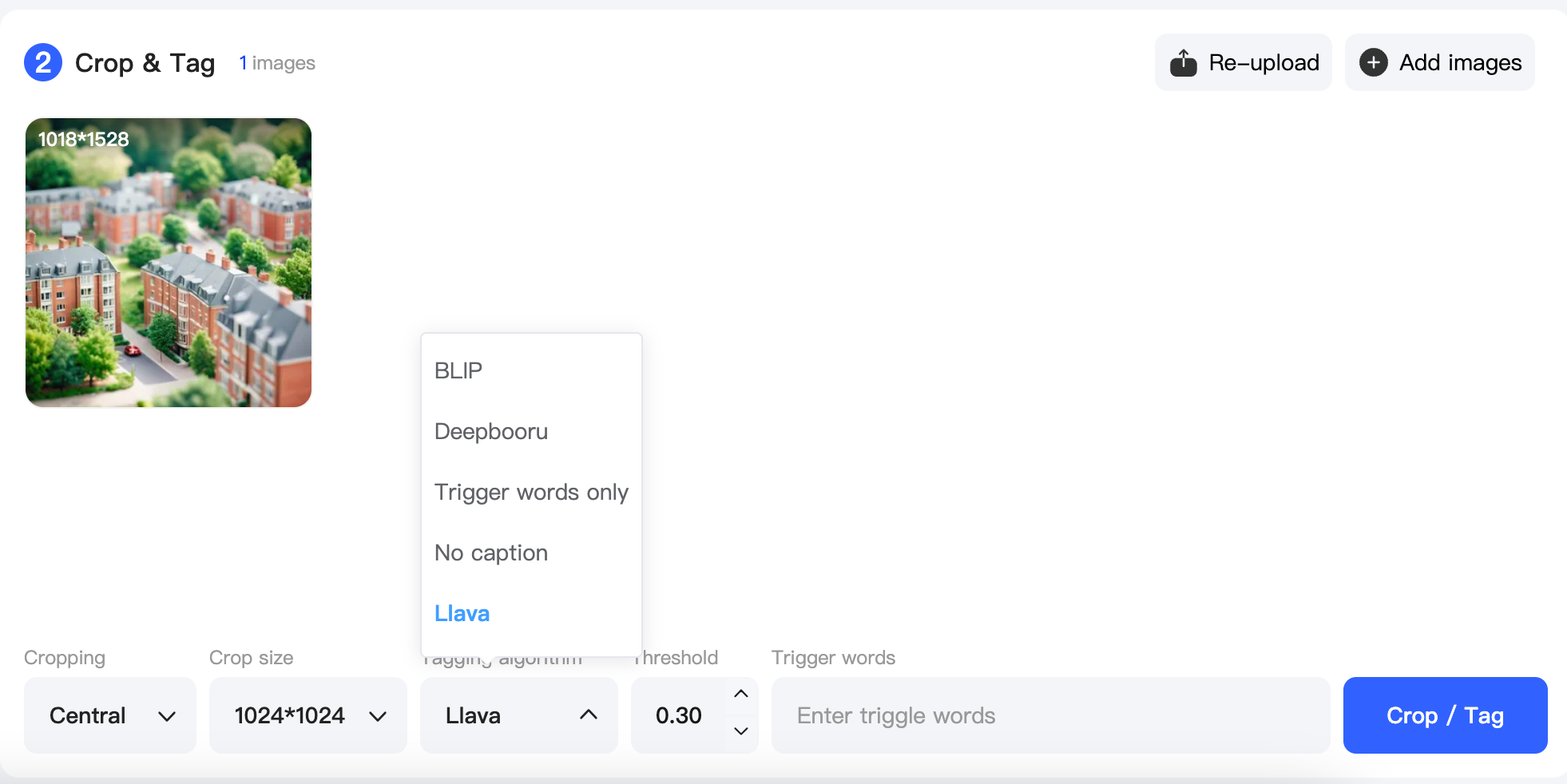
¶ Why Use Labeling?
- Enhancing Model Generalization
Diverse and comprehensive annotations enable the model to learn a wider range of image features and patterns. Labeling various images with different scenes, poses, and lighting conditions allows the model to understand these nuances.
For instance, when training a clothing-specific model, annotating a variety of images with different styles, colors, and lengths ensures the model can accurately generate specific clothing based on particular prompts, such as style or color.
- Accelerating Model Convergence
Accurate annotations help the model achieve better performance faster. During training, the model adjusts its parameters to fit the labeled data. High-quality, representative labels reduce uncertainty and exploration, enabling the model to converge quickly and efficiently. This reduces training time and resource consumption.
¶ Labeling Models Overview
| Labeling Method | Description | Output Format Example | Recommended Use Case |
|---|---|---|---|
| BLIP | Generates natural language labels in complete sentences, providing detailed descriptions of actions, poses, or features. | A woman is running in a black dress. | Best for scenarios requiring detailed descriptions or capturing specific nuances in actions and poses. |
| Deepbooru | Produces labels in concise tag format, focusing on key details in a word or phrase. | A woman, running, black dress. | Suitable for general object recognition or when processing time is critical. Recommended for Base Algorithm 1.5 models. |
| Trigger Words Only | Creates direct associations between trigger words and specific style features in the dataset. For instance, using "cartoon style" as a trigger word links it to features like simplified lines, exaggerated colors, or unique proportions. While trigger words allow precise style correlation, they lack the supervised learning needed for accuracy, making training and optimization more challenging. | Trigger word: "katong001" (e.g., for "cartoon style") | Useful for generating specific styles. Always recommended as an additional feature for all models but not as the sole labeling method. |
| No Labeling | Skips the labeling process entirely. However, this significantly impacts performance, model generalization, and explainability. Models trained without labels often fail to perform reliably, struggle with convergence, and lack interpretability. | None | Not recommended. Skipping labeling negatively affects the model's quality, training efficiency, and real-world application. |
| Llava | Generates natural language annotations like BLIP but with higher efficiency and stronger visual-text correlation. Llava achieves better accuracy but requires longer processing time. | A woman, running, black dress. | Recommended for Base Algorithm XL and Base Algorithm F.1 models, especially when precise visual-text pairing is needed. |
Recommendations
-
For models based on Base Algorithm 1.5, Deepbooru is recommended for labeling.
-
For models based on Base Algorithm XL or Base Algorithm F.1, use BLIP or Llava for better results.
-
It is recommended to add trigger words in all model types to facilitate intuitive style generation.
-
Avoid skipping labeling, as it significantly undermines model quality and usability.
Note: Adding trigger words helps in efficiently generating images with specific styles, enhancing the model's ability to associate visual elements with clear instructions.
¶ Step 4. Choosing the Right Base Model
Selecting an appropriate base model is a critical step in training a LoRA (Low-Rank Adaptation) model. A well-chosen base model can significantly enhance the performance and effectiveness of the resulting LoRA model. But why is this so important? Let’s uncover the reasons:
¶ 1. The Role of the Base Model in LoRA Training
| Benefits | Explanation | Example |
|---|---|---|
| Provides Foundational Features | The base model serves as the foundation for LoRA training, offering a set of pre-learned features. During training, LoRA parameters fine-tune these features to adapt them to specific tasks or styles. | For instance, when training a model for a specific artistic style, the base model supplies the fundamental structure and features of images, while LoRA refines them for style-specific generation. |
| Accelerates Training | Pretrained on large-scale datasets, the base model already contains extensive knowledge of general image features and patterns. This prior knowledge allows the LoRA model to train faster compared to starting from scratch. | By leveraging the base model, training time and computational resources are significantly reduced. |
| Improves Generalization | The general-purpose design and large parameter size of the base model enhance the model's generalization ability. LoRA fine-tunes this foundation, combining general capabilities with task-specific optimization. | As a result, the LoRA model performs better on new data and tasks, effectively inheriting the base model's versatility while adding specificity. |
¶ 2. Characteristics of a Base Model for LoRA Training
-
Rich Feature Learning
A base model, trained on extensive datasets, has already learned a wide range of image features. These include fundamental attributes such as object shapes, textures, and colors, as well as higher-level semantic features.- For example, a base model trained on the ImageNet dataset can recognize a variety of object categories and deeply understand their distinguishing features.
-
Versatility
The versatility of a base model allows it to be applied to diverse tasks and scenarios. While it may not be optimized for a specific task, it serves as a strong starting point for various applications.- For instance, a base model designed for photorealistic imagery can still be adapted for generating anime-style artwork through fine-tuning, enabling it to meet specific generation requirements.
-
Large-Scale Parameters
Base models typically possess a large number of parameters, which enables them to capture complex and rich image information. However, training such models directly requires substantial computational resources and time.- In LoRA training, the base model's parameters are usually frozen, and only a small set of LoRA parameters are trained, significantly reducing the resource demands while retaining the model's robust feature set.
¶ 3. Why Choose a Base Model Aligned with the Training Style?
Selecting a base model that aligns with the target training style can significantly enhance the performance of LoRA models. Here’s how this approach proves advantageous:
¶ 01. Improved Style Adaptation
- Higher Feature Compatibility:
Different artistic styles possess unique characteristics, such as color usage, line expression, and texture details. Choosing a base model trained on similar styles means it has already learned features relevant to the target style during large-scale training.
- Example: When training a LoRA model for an oil painting style, selecting a base model pretrained on a large dataset of oil paintings ensures it has already captured common features such as color gradients and brushstroke effects. This allows the LoRA model to fine-tune these features more effectively, leading to better results in generating oil painting-style images.
- Enhanced Style Consistency:
Combining a style-consistent base model with a LoRA model ensures that the generated images maintain a unified aesthetic.
-
Issue Example: Using a realism-focused base model to train a cartoon-style LoRA model may leave traces of realism in the generated cartoons, resulting in inconsistent style.
- Solution: Selecting a base model with matching stylistic traits ensures the generated images are pure and consistent in style, avoiding any mismatched elements.
¶ 02. Optimized Training Efficiency
- Faster Convergence:
When the base model’s style aligns with the target style, the LoRA model can quickly identify the optimal direction for parameter adjustments, speeding up convergence.
- Why: The base model already provides a starting point close to the target style, so the LoRA model only needs minor adjustments to achieve optimal results. In contrast, a base model with significant stylistic differences requires more time to explore and adjust parameters, slowing the convergence process.
- Improved Training Stability:
A style-aligned base model can enhance the stability of the training process.
-
Reason: A base model trained on style-relevant data is naturally more adaptive to similar styles, reducing the risk of overfitting or underfitting during LoRA training.
- Example: Training a watercolor-style LoRA model using a base model pretrained on watercolor datasets results in more stable training, avoiding drastic fluctuations or instability in the process.
By selecting a base model aligned with the target training style, you can improve feature compatibility, enhance style consistency, accelerate convergence, and ensure stable and effective training.
¶ 4. Recommended Base Models for Common LoRA Training Styles
Selecting the right base model for LoRA training is crucial as it significantly impacts the quality and efficiency of the results. Below are recommendations for commonly used styles and their respective base models:
| Base Model Version | Style | Recommended Base Model | Key Features |
|---|---|---|---|
| Base Model 1.5 | Realistic | ChilloutMix | - Highly realistic and lifelike images - Asian aesthetic compatibility - Strong prompt response capabilities - High-quality image outputs - Excellent compatibility for adjustments |
| Anime | AnythingV5 | - High-quality outputs for 2D and anime-style images - Minimal keyword input required - Consistent style - Excellent for producing detailed anime images | |
| CG | Revanimated | - Suitable for fantasy-style CG artwork - Western facial aesthetics - Effective in creating fantasy or sci-fi settings - Can simulate 3D-rendered animation styles | |
| Base Model XL | Realistic | 9realisticSDXL | - Excellent for hyper-realistic image generation - Strong performance in character rendering and lighting - Ideal for realism-focused tasks |
| CG/Anime | LeoSAM HelloWorld | - Fine-tuned for sci-fi, animal, architecture, and illustration - Performs well in creating specific fantasy or creative-themed works | |
| Base Model F.1 | General Use | F.1 Original Model | - High-performance capabilities - Suitable for most training tasks - No additional base model required |
By choosing the right base model for your target style, you can optimize LoRA training for better style adaptation, faster convergence, and higher-quality results.
¶ Step 5. Adjusting Training Parameters
¶ 1. Key Parameters
Parameters play a critical role in model training as they directly impact the model's performance, training efficiency, and final results. Below are some essential parameters, explained with practical analogies to highlight their importance. For a more detailed overview, visit Training Tool Glossary.
¶ a. Learning Rate
-
Definition:
Learning rate is one of the most important parameters in model training. It determines the step size for adjusting model weights based on the gradient of the loss function during each iteration.-
If the learning rate is too high, the model may overshoot the optimal solution, causing the training to diverge or result in an increasing loss.
-
Conversely, if the learning rate is too low, the model will converge very slowly, significantly increasing training time, especially for large datasets or complex models, and potentially leading to inefficient training.
-
-
Analogy:
Imagine a child learning to distinguish between apples and oranges.-
A high learning rate is like the child drastically changing their judgment based on one small feature: for example, hearing that apples are red and mistaking a slightly red orange for an apple. This results in confusion, just like a model failing to converge.
-
A low learning rate is like the child making tiny adjustments each time they learn, requiring a long time to correctly differentiate apples and oranges—akin to a model with slow convergence.
-
¶ b. Batch Size
-
Definition:
Batch size determines the number of samples fed into the model during each training iteration. It affects both the training speed and stability.-
Larger batch sizes utilize GPU parallelism efficiently, accelerating training. However, they can cause memory issues on hardware with limited resources.
-
Smaller batch sizes may introduce noisier gradient estimates, which can sometimes help the model escape local minima but may also slow down the training process.
-
-
Analogy:
Imagine moving a stack of books to a shelf:-
Using a large batch size is like carrying many books at once. If you’re strong enough (sufficient memory and computation power), this is efficient. If not, you risk dropping the books.
-
Using a small batch size is like carrying just a few books at a time. It’s slower but more manageable, especially if you’re less strong. Along the way, you might even notice better ways to organize the books (escape local minima).
-
¶ c. Training Epochs
-
Definition:
Training epochs represent the number of times the entire dataset is passed through the model. While sufficient epochs allow the model to learn patterns and features in the data, too many epochs can lead to overfitting. Overfitting occurs when the model learns noise or specific details in the training data, reducing its ability to generalize to new data. -
Analogy:
Think of training as a student studying for an exam:-
Too few epochs are like the student not reviewing the material enough, resulting in poor test performance.
-
Too many epochs are like the student memorizing specific questions instead of understanding the concepts. This makes it difficult to handle new or slightly modified questions in the exam (overfitting to training data).
-
¶ d. Regularization Parameter
-
Definition:
Regularization parameters help control model complexity to prevent overfitting and ensure the model doesn’t excessively fit to noise in the training data. -
Analogy:
Imagine creating a sculpture:-
Without any restrictions, the sculptor (the model) may over-carve details, leading to an odd-looking sculpture that doesn’t work well in other settings (new data).
-
A regularization parameter acts like guidelines for the sculptor, ensuring they focus on the overall shape and style (general patterns) instead of overemphasizing unnecessary details.
-
¶ e. Optimizer-Specific Parameters
-
Definition:
Different optimizers have distinct parameters that influence how the model’s weights are adjusted. Choosing the right optimizer can help the model converge quickly and stably to an optimal solution, improving its performance and generalization ability across various applications and datasets. -
Analogy:
Selecting the right optimizer is like choosing the best running shoes and strategy for a marathon. A good combination ensures you perform at your best and reach the finish line efficiently.
By carefully adjusting these parameters, you can significantly improve the efficiency, stability, and final performance of your model, making it better equipped to handle new challenges and data.
¶ 2. Adjusting Training Parameters for Different Datasets
When preparing to train a model, it’s tempting to use the same parameters that others have shared online. However, the results often fall short of expectations. You might wonder why identical parameters yield excellent results for others but only average outcomes for you. The reasons can be summarized into the following four key points:
¶ 1. Differences in Image Content
Training datasets vary significantly in content. For example, one dataset might consist of landscapes, while another features portraits.
-
Landscape Images: Focus on characteristics such as color, texture, and spatial composition. Parameters should be adjusted to capture elements like mountains, rivers, and skies more effectively.
-
Portrait Images: Emphasize details like facial features, expressions, and skin tones, requiring a different set of parameter adjustments tailored to these aspects.
¶ 2. Diversity of Image Styles
If the training dataset includes a variety of styles (e.g., realistic, cartoon, abstract), the parameters need to be adjusted accordingly:
-
Uniform Style Dataset: When the dataset features a consistent style, the model can converge more quickly. In this case, more aggressive parameters (e.g., faster learning rates) can be used.
-
Diverse Style Dataset: For datasets with mixed styles, the parameters must be fine-tuned to ensure the model captures the characteristics of each style. This might involve slower learning rates and stronger regularization techniques to prevent the model from favoring one style over others.
¶ 3. Risk of Overfitting
Training datasets vary in complexity and size, which can affect the risk of overfitting:
-
Smaller or Less Diverse Datasets: These are more prone to overfitting, as the model might memorize the specific patterns in the dataset rather than generalizing. To address this:
-
Increase the intensity of data augmentation (e.g., rotation, flipping, scaling).
-
Reduce the learning rate.
-
Add more regularization techniques.
This ensures the model has better generalization abilities instead of just memorizing the training data.
-
¶ 4. Risk of Underfitting
Conversely, for large or complex datasets, improper parameter settings can lead to underfitting:
-
Causes of Underfitting: If the learning rate is too low or the training cycle is too short, the model may fail to learn the dataset's features effectively.
-
Solution: Adjust the parameters based on the dataset’s size and complexity:
-
Increase the learning rate appropriately.
-
Extend the training cycles.
These adjustments ensure the model can effectively learn the dataset’s features and avoid underfitting.
-
In summary, to achieve optimal training results, it’s crucial to customize the training parameters based on the content, style diversity, size, and complexity of your dataset. This tailored approach helps strike the right balance between underfitting and overfitting, resulting in a well-trained model.
¶ Model Evaluation Criteria
Once the model has been generated, the most intuitive way to assess its performance is through image generation testing, based on the following evaluation criteria:
¶ 1. Image Quality
-
Image Clarity:
For a LoRA model generating images, the output should be clear and rich in detail. For example, when generating a landscape image, the contours of distant mountains and the textures of nearby leaves should be sharp and distinguishable, without any blurriness or pixelation. Clarity can be evaluated by visually inspecting the generated image. -
**Content Accuracy:**The content generated by the model should align with the given prompt. For instance, if the prompt specifies generating a character in ancient attire, the generated image should accurately depict details such as the collar style (e.g., right-over-left) and traditional hairstyles. Comparing the output with the prompt can be used to evaluate accuracy.
-
Style Consistency:
When the model is tasked with generating content in a specific style, such as oil painting or anime, the output should maintain consistency in aspects like color, brushstrokes (for oil painting), or lines (for anime). For example, oil painting style images should feature rich colors and distinct brushstroke marks, and these stylistic features should be consistent throughout the image.
¶ 2. Diversity and Creativity
-
Diversity:
When given the same or similar prompts, the model should generate a variety of distinct outputs. For example, when prompted with "generate a fantasy creature," the model should produce fantasy creatures with varying shapes, colors, and features, rather than generating similar images each time. Diversity can be assessed by repeatedly using the same prompt and observing the differences in results. -
Creativity:
The model should be capable of generating novel and unique content. For instance, when generating architectural designs, the model should not only produce conventional architectural styles but also create new combinations of styles or entirely original concepts, showcasing creative thinking.
¶ 3. Generalization Ability
-
Adaptability to Different Prompts:
The model should not only perform well with the specific types of prompts it was trained on but should also generate reasonable content for new, related prompts that were not present in the training dataset. For example, a model trained to generate ancient clothing for historical figures should be able to generate images of mythological characters' clothing when presented with a new prompt, adhering to the mythological theme and ancient clothing style. -
Adaptability to Different Datasets:
When the model is tested on a new dataset that slightly differs from the training data, it should maintain its performance. For instance, a LoRA model trained on an anime character dataset in a specific style should still be able to generate images in that style when applied to another large anime dataset from a different artist, demonstrating its ability to adapt to variations within the same style.
In addition to using the most direct method of evaluating model quality through image generation, the training logs in the Shakker AI training tool can also provide insight into the training process.
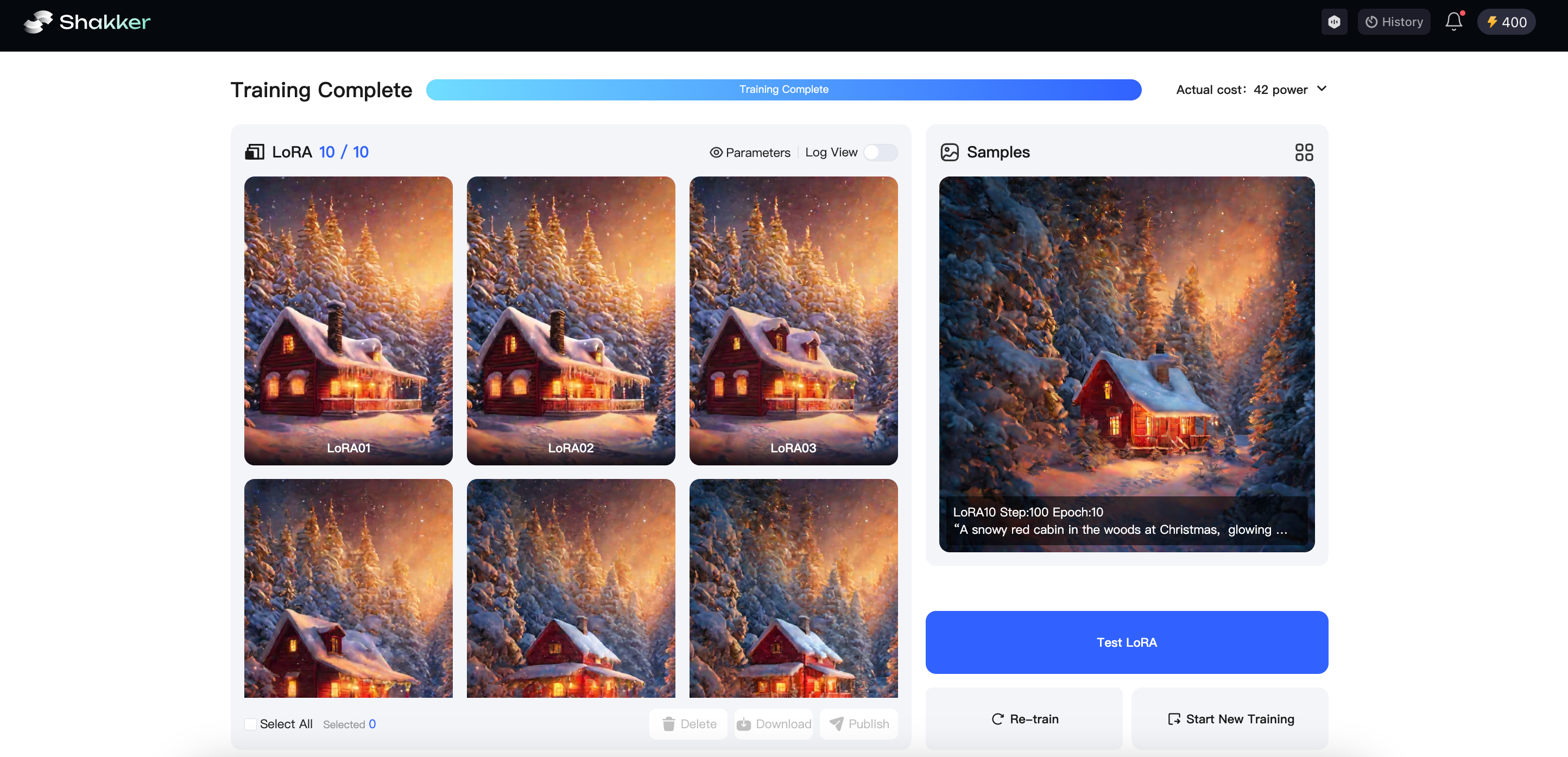
Training Log Interpretation:
The "Loss/Average" section displays the average loss value, an important indicator of the model's training effectiveness. The loss value reflects the gap between the model's predicted results and the true outcomes. A lower loss value typically indicates better model performance.
During training, if the average loss value consistently decreases, it indicates that the model is learning and improving. A rapid decrease in the loss value means the model is learning quickly, while a slow decrease may suggest the need to adjust training parameters, such as increasing the number of training epochs or adjusting the learning rate, to enhance training effectiveness. If the loss value remains high or fluctuates significantly, it could signal issues with the model, such as overfitting or data problems.
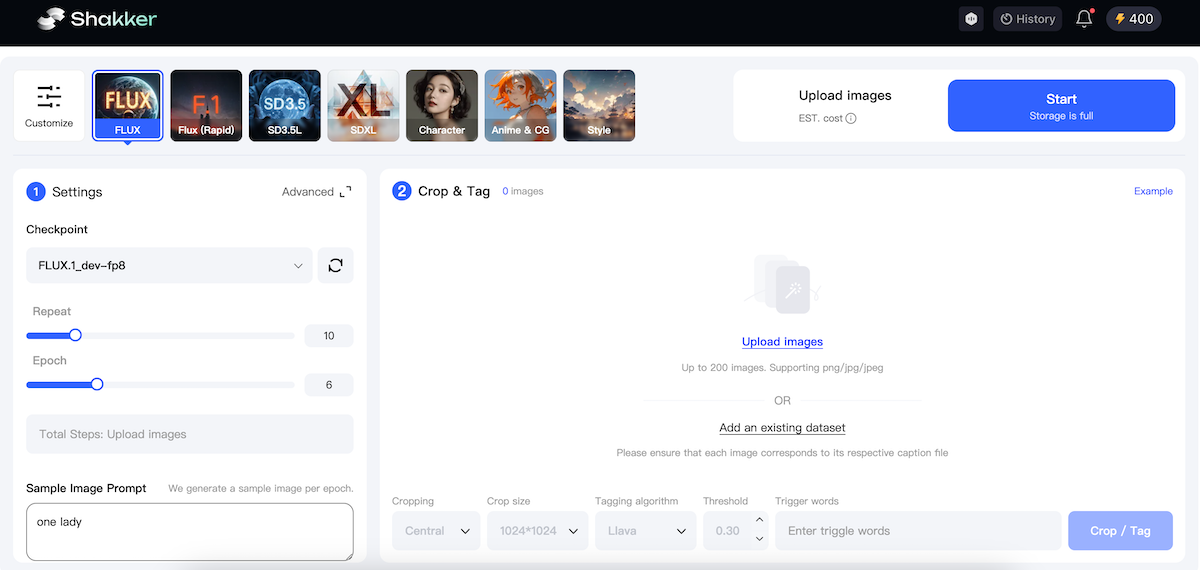
¶ The Easiest Way to Train a LoRA Model
At the top of the interface, we have provided five preset training options. You only need to select one to apply. Since this case is focused on lipstick e-commerce products, we can choose the portrait preset. Here’s what we need to do:
- Upload Training Images
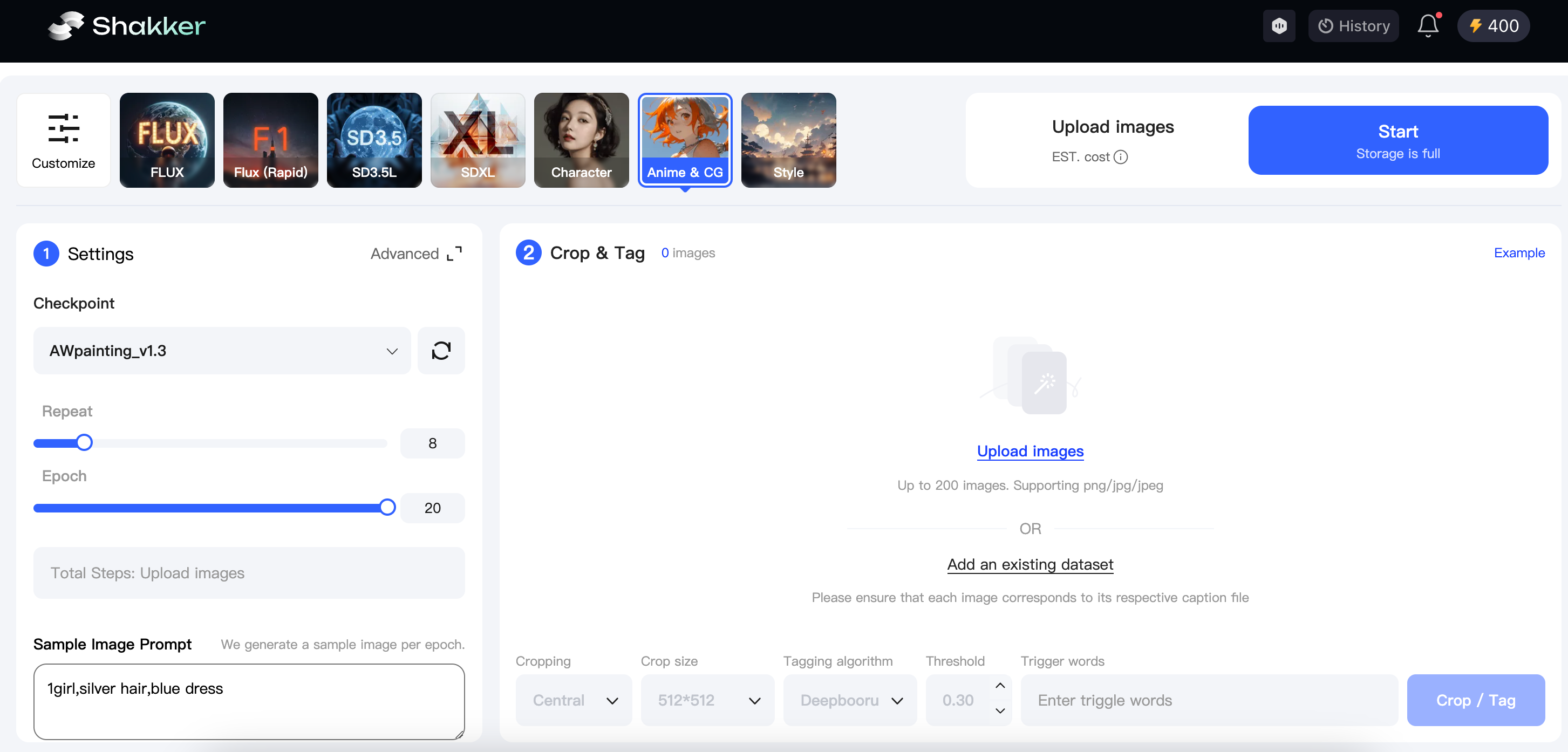
- Adjust Training Images to Optimal Resolution
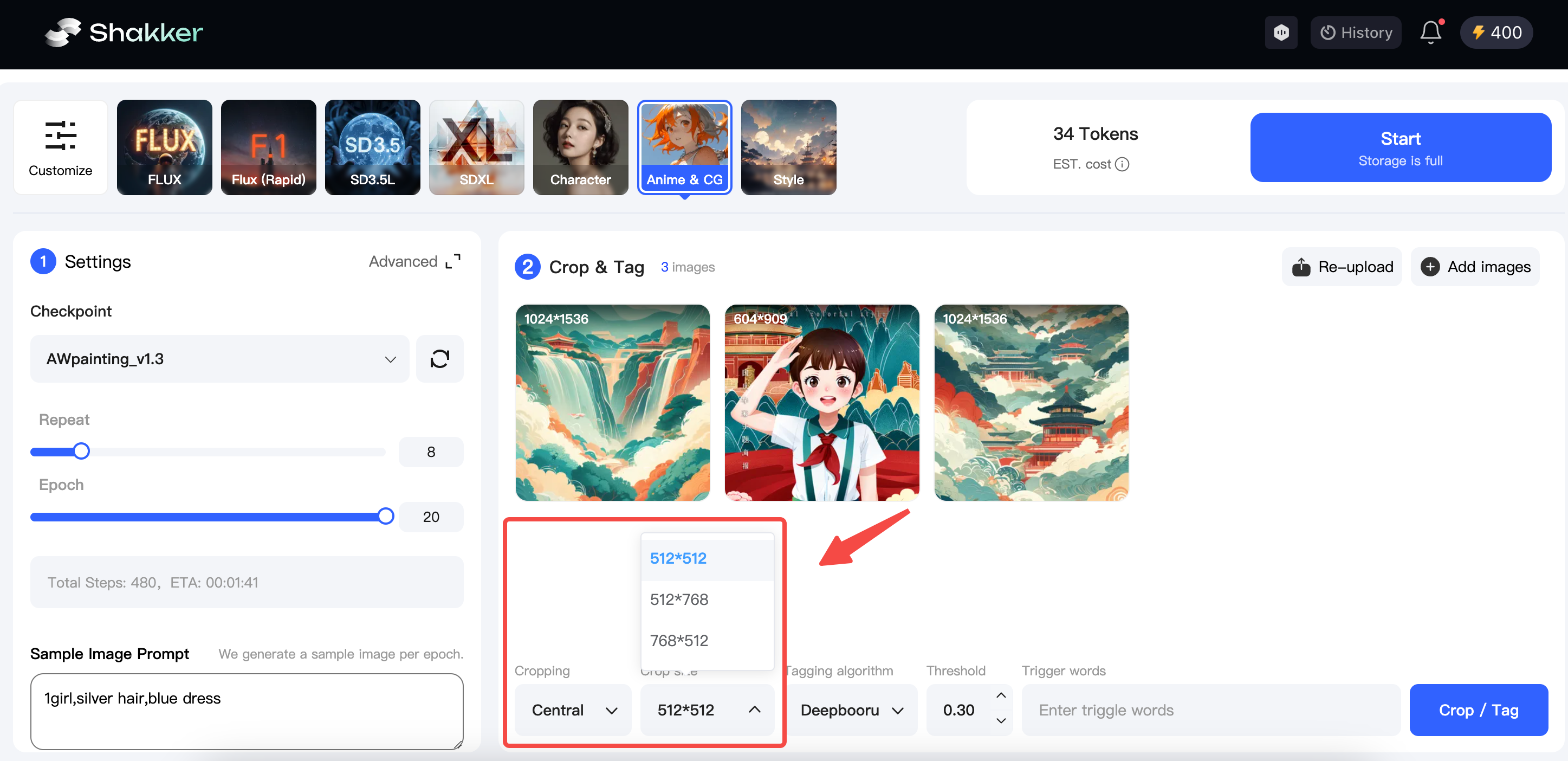
The Shakker AI online training tool offers three cropping methods and three size options to help you crop images with just one click. Here, I’ll choose the focus crop and the 512x768 cropping size to adjust the image resolution.
- Select Labeling Method Based on Model Type
The Shakker AI online training tool provides five labeling methods to assist you in labeling your images with just one click.
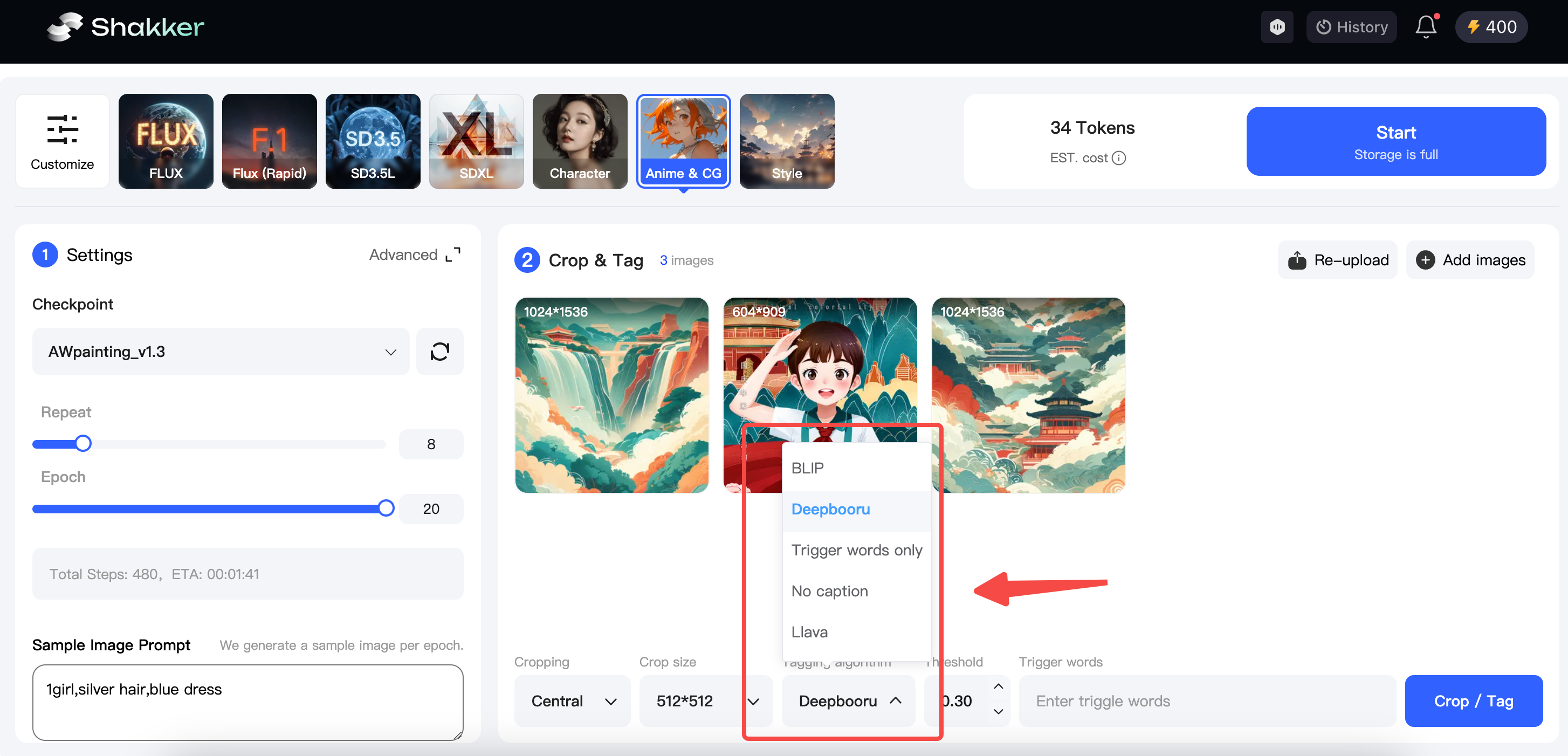
Since I’m using Base Model 1.5 as the base, I’ll choose Deepbouru for labeling and then set the model trigger word to “chocolate.”

- Train Again Based on Model Effectiveness
(1) Check Training Logs to Evaluate Results
After the model is trained, we need to test it. Let’s first look at the log view provided by the Shakker AI online tool.
A good log view should show a general downward trend (ideally decreasing by around 0.1), but with some minor rebounds along the way. Looking at the model trained earlier, the overall average loss value shows a downward trend, from 0.16 gradually dropping to 0.13. This indicates that the model is continuously learning and optimizing, progressively improving its ability to fit the data.
What does an abnormal log look like?
A Direct, Uninterrupted Drop in the Curve:
If the curve drops steadily without any rebounds, it could indicate that the model has converged too quickly. On one hand, this might suggest that the model has found a reasonably ideal solution on the training data and quickly optimized towards that goal, causing a sharp decline. However, this rapid convergence may cause some issues: if training stops prematurely, the model may not have undergone sufficient training, leading to subpar performance on larger models outside the base. Alternatively, it could indicate that the training data is too simple and features are too obvious, allowing the model to easily learn the training dataset’s features, resulting in a sharp decline without rebounds. Additionally, overfitting may occur: the model performs extremely well on the base data but poorly on fine-tuned images outside the base.
Also, the learning rate plays a role. If it’s set too high, the model might drop quickly early on but may miss better solutions and fail to adjust adequately afterward.
A High, Stagnant Curve:
If the curve remains high without decreasing, the problem might lie with the training dataset. If the training set is too small, the model might not fully learn the features of the data. For complex training needs, a larger dataset is necessary for the model to capture diverse situations and variations. With insufficient training data, the model may overfit, leading to poor performance during image generation, and the curve won’t decrease. Furthermore, if the learning rate is too high, the model might skip optimal solutions, preventing the loss function from converging. A high learning rate may also cause instability during training, with large fluctuations in the curve. On the other hand, if the learning rate is too low, the model may take too long to optimize and won’t reach a satisfactory result quickly, leading to a persistently high curve for an extended period.
(2) Evaluate Results Based on Generated Images
Once the model is trained, we move to the visual generation phase. Click the “Generate Model Image” button at the bottom right of the training section to access the Shakker AI online image generation tool.
Click the model interface button and then go to the LoRA interface and click on “My Training.” Here, you’ll find the model we trained.
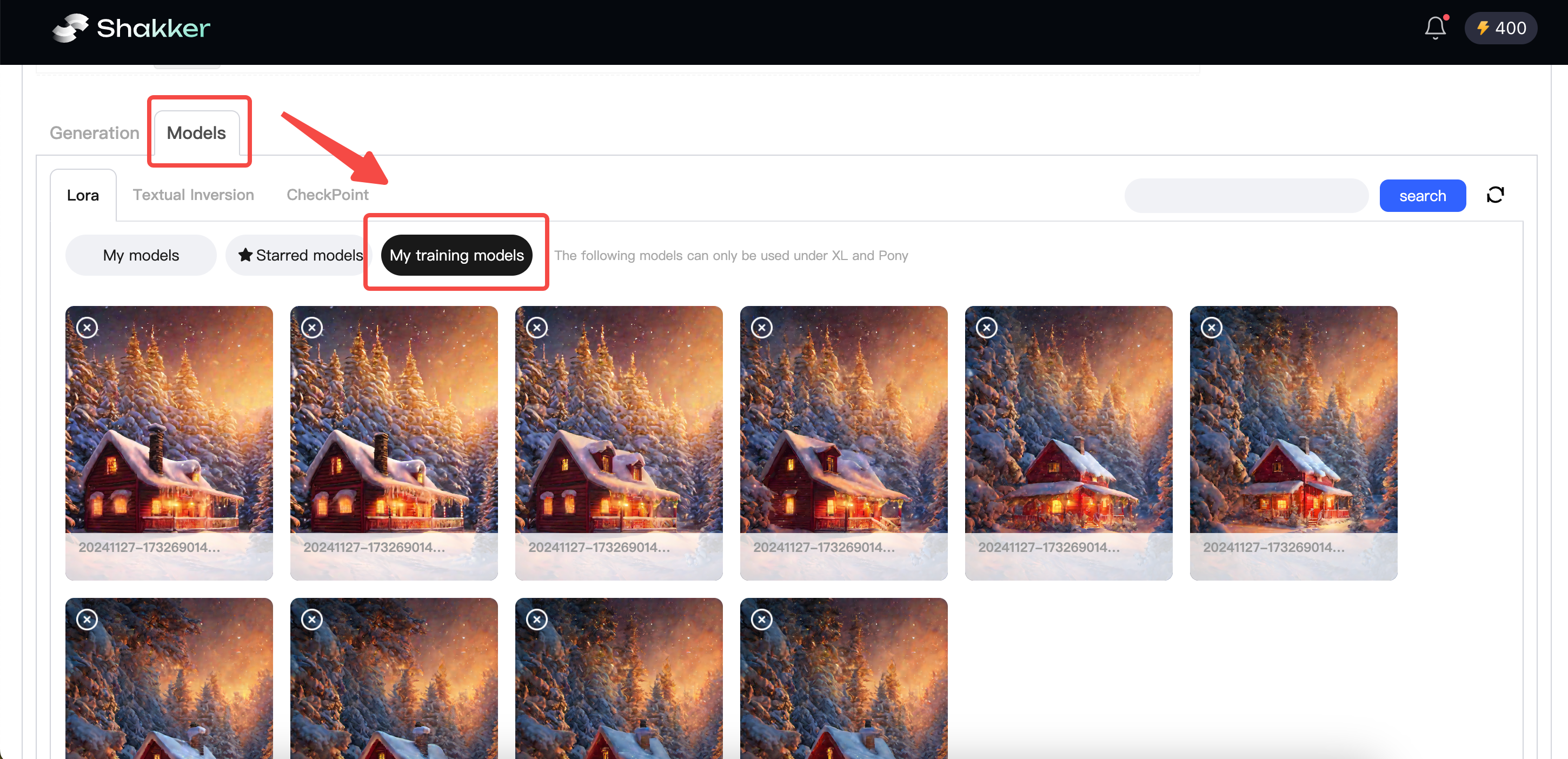
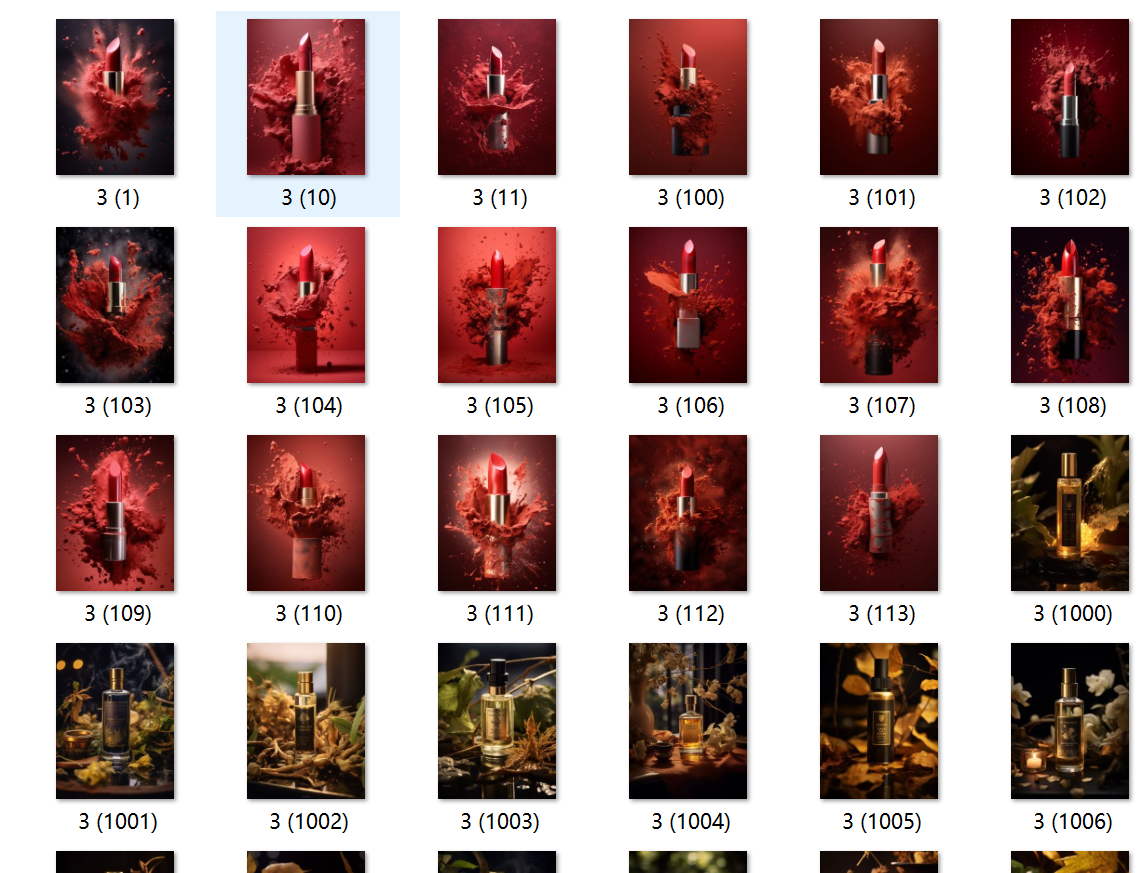
Choose one of the LoRA models we trained and enter the parameters. Since this is a lipstick product training, I’ll use the trigger word “chocolate” and add some lipstick-related adjectives for the image generation test.
Image Generation Test
Overall, the results are promising. The model accurately generates the image we want, indicating that the model has fit well. However, two of the images are a bit off, likely due to overfitting. To fix this, we can retrain the model by lowering the learning rate or reducing the number of training steps, among other adjustments.
In this course, we systematically learned how to train a LoRA model using the Shakker AI online training tool. I hope you’ll be able to train a satisfactory LoRA model in your future attempts. See you next time!